Protect Amazon API Applications with Incident Response
Incident response measures to protect Amazon SP-API applications.
Overview
This whitepaper provides guidance on what constitutes an incident response plan and the mechanisms required to handle an incident. Having a well documented incident response plan helps organizations identify, detect, and respond to risk management failures quickly. The plan should be regularly reviewed, revised to facilitate immediate handling of incidents should one occur, and incorporate lessons learned.
Data protection policy requirements
As a requirement, developers should create and maintain a plan to detect and handle security incidents. Such plans should identify the incident response roles and responsibilities, define incident types that can impact Amazon, define incident response procedures for defined incident types, and define an escalation path and procedures to escalate Security Incidents to Amazon. Developers should review and verify the plan every six months and after any major infrastructure or system change. Developers should investigate each security incident, and document the incident description, remediation actions, and associated corrective process/system controls implemented to prevent future recurrence (if applicable). Developers should maintain the chain of custody for all evidences or records collected, and such documentation should be made available to Amazon on request (if applicable).
Developers should inform Amazon (via email to security@amazon.com) within 24 hours of detecting any security incidents. Developers cannot notify any regulatory authority, nor any customer, on behalf of Amazon unless Amazon specifically requests in writing that the Developer do so, unless required by law. Amazon reserves the right to review and approve the form and content of any notification before it is provided to any party, unless such notification is required by law, in which case Amazon reserves the right to review the form and content of any notification before it is provided to any party. Developers should inform Amazon within 24 hours when their data is being sought in response to legal process or by applicable law.
Incident response
Developers should understand security incident response (IR) processes, and security staff should understand how to respond to security issues. Developers without a dedicated security team should 1) ensure a portion of the organization is sufficiently trained and equipped with tools to perform such activities and/or 2) consider establishing one. Developers who wish to build a mature security team should consider this best practice: integrate the flow of security events and findings into a notification and workflow system. Such systems include ticketing systems, a known/technical issue system, or other security information and event management (SIEM) system.
Developers should start small, develop runbooks, leverage functional capabilities, and create a library of incident response mechanisms to iterate from and improve upon. This should include teams that are not involved with security, including the legal department. In this way, developers will understand the impact that IR has on business objectives.
Developers should consider using industry guidelines such as NIST’s SP 800-61R2: Computer Security Incident Handling Guide. This NIST guide includes a checklist providing the major steps to perform during an incident. Developers should consider using the checklist as a template while developing a plan. They may develop a specific plan to reflect the organization’s functions, objectives, risks, and mitigating actions. Each of these is dependent upon the size and complexity of the organization and its systems.
Throughout this whitepaper, we will refer to the United States’ National Institute of Standards and Technology’s (NIST) Security and Privacy Controls for Information Systems and Organizations (Special Publication 800-53 Revision 5), commonly referred to as NIST 80053 as a reference. This developing framework provides flexible controls to protect organizations from security and privacy threats. Developers should consider using this framework to implement and strengthen their organizational controls.
Foundation of incident response
Incident response plans, often referred to as procedures or runbooks, define the steps to investigate and remediate an incident. Experience and education are vital to implementing an incident response program before handling a security event.
An event is any occurrence in a system or network, ranging from acceptable events (e.g., a known user logging into a computer) to an adverse event (e.g., an unknown user logging into a computer). Such adverse events can lead to an incident, such as a violation of computer security policies, acceptable use policies, or contractual requirements.
Developers who wish to use NIST 800-53 to establish an IR plan may examine section IR-8: Incident Response Plan. IR-8 details the necessary components in implementing an IR plan. Such components include:
-
Defining the resources and management support needed.
-
Reviewing and approving the plan at a defined cadence.
-
Designating responsibility for IR to appropriate personnel.
As Developers implement this control, they may achieve compliance with Amazon DPP requirements. This includes reviewing and verifying the plan every six months and informing Amazon within 24 hours of detecting any incidents.
Security events
A well-defined incident response plan includes response mechanisms for different types of security events. Developers should consider using diagrams to map the relationship between threats and the appropriate response mechanisms. For example, the Johari Window, created in 1955 by Joseph Luft and Harrington Ingham, is a grid that consists of four quadrants, as depicted below:
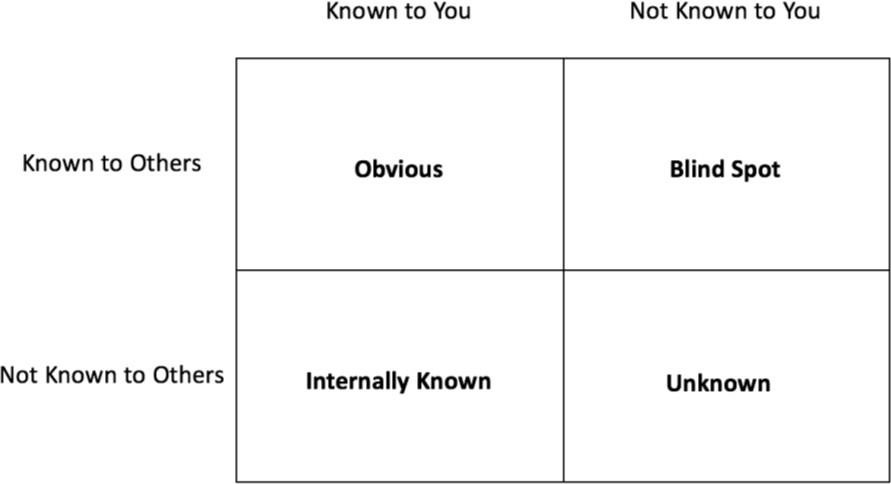
Types of security events
Although the Johari Window was not intended for information security, it can help developers understand how to assess an organization's threats. In the incident response-based concept, the four quadrants are: Obvious, Internally Known, Blind Spot, and Unknown threats. For each incident type, developers should define incident response procedures to verify they are adequately prepared to respond. As developers define those types, they should consider the threats relevant to both partners and suppliers. Include contact information and identify the point at which the tools and systems notify personnel within the organization. This is required to comply with service level agreements in regulatory and contractual obligations, including with Amazon.
Obvious
Obvious threats are risks of which both developers and their partners, such as Amazon, are aware. For example, malicious actors commonly employ Denial of Service (DoS) attacks against organizations. In a DoS attack, a malicious actor temporarily or indefinitely disrupts the application’s ability to connect to the internet. developers should employ mechanisms to protect services from intentional malicious interruption. Developers should consider defining minimally acceptable downtime recovery goals for DoS attacks.
Malicious actors commonly attempt to invade, and even control, organizations by intruding into their applications. Developers can mitigate intrusion attempts by implementing Intrusion Prevention Systems (IPS) and Intrusion Detection Systems (IDS). Each system examines network traffic flows to detect if an intruder is attempting to access the system. In the case of an IPS, the system prevents unauthorized users from entering. However, if an intrusion is successful, an IDS will send a notification to trigger a response.
Internally known
Internally known threats are those that the developer is familiar with, but their partners (such as Amazon) are not. This includes internal expertise or institutional knowledge. For example, the development team can have undocumented yet established practices for managing configuration changes. However, there are risks in having undocumented process. For example, the team:
-
Might not be confident that all changes are tested and approved.
-
Might not have rollback mechanisms in case code releases did not work as intended.
-
Might not scan for technical issues in new production releases.
Developers should consider these scenarios to mitigate internally known threats.
Additionally, insider risks, such as an employee’s malicious or unintentional action, might harm the environment. Access management controls and data loss prevention mechanisms help prevent and detect such actions. Limiting unauthorized data access, both from internal and external entities, is a critical step in securing and protecting data. Developers should employ the principle of least privilege, granting only the access necessary for a person or program to complete its task. It is best practice to delete default access accounts and limit the use of shared accounts. If necessary, developers should monitor shared accounts to validate that they are only used when necessary. Shared accounts should only be shared after the appropriate administrators approve their use. Developers may supplement these monitors with data loss prevention controls. This prevents inadvertent sharing of confidential or critical information with unauthorized parties. That information may even include encryption keys or application credentials (e.g., embedded in code and exposed in GitHub) that can bypass the controls.
Blind spot
Blind spots are risks that a partner is familiar with, but the developer is not. A partner with the right expertise can share that knowledge. Such risks may be Common Vulnerabilities and Exposures (CVEs) that affect applications without the owner’s knowledge. Although Developers might be familiar with those risks in the Obvious quadrant, a partner could recommend controls and solutions that the developer is unfamiliar with. Additionally, a partner may be equipped to identify fine-tuned controls for mitigating risks in the internally known quadrant.
Other blind spots include the changing regulatory environment. The European Union’s General Data Protection Regulation (GDPR) affects businesses worldwide, and similar regulations, such as the California Consumer Privacy Act (CCPA), are quickly arising. Such regulations can affect response mechanisms and notification methods.
Monitoring the external environment helps mitigate these risks. Specifically, the National Vulnerability Databases (NVDs) helps organizations understand the latest vulnerabilities and their risk scores. Such scores, led by the Common Vulnerability Scoring System (CVSS), enumerate a technical issue’s severity, taking into account its complexity and impact. Developers should stay abreast of industry updates, regulatory changes, and contractual requirements. Requirements change frequently and may require developers to improve internal processes to remain compliant. Developers should meet with partners regularly to understand blind spots and mitigate them. While measuring for improvement, developers may consider contacting Amazon, via the Amazon Services Support page, to get expert advice on protecting their Amazon SP-API application.
Unknown
Unknown threats are risks which neither developers nor their partners are familiar with. Implementing and reviewing monitoring mechanisms can identify indicators of security events.
Indicators of security events
Developers should investigate all security events to ensure that they do not develop into security incidents. Though not exhaustive, developers should consider the following list of potential indicators of security events:
-
Logs and monitors. A sudden change in computing activity, as indicated by monitoring tools and logs, can indicate a security event.
-
Unusual billing activity. A sudden increase in billing activity can indicate a security event. This billing activity might arise from compute-intensive processes that an intruder might initiate, such as bitcoin mining.
-
Threat intelligence feeds. If your organization subscribes to a third-party threat intelligence feed, correlate that information with other logging and monitoring tools to identify potential indicators of events.
-
Data integrity. Data in a service or application returns unexpected values.
-
Data exposure. Sensitive data is exposed to unauthorized or unintended parties.
-
Lack of availability. An application or service cannot fulfill its functions.
-
Public-facing security contact mechanism. A well-known, well-publicized method of contacting the security team can inform developers of an incident. Customers, the development team, or other staff might notice and report something unusual. Developers who work with the general public might need to develop a public-facing security contact mechanism, such as a contact email address or a web form.
-
System alerts. Internal systems may generate notifications that alert in case of unusual, malicious, or expensive activities. For example, developers may create a notification for activities that occur outside of expected time frames.
-
Machine learning. Developers can leverage machine learning to identify complex anomalies for a specific organization or individual person. Developers can profile the normal characteristics of the networks, users, and systems to help identify unusual behaviors.
Define roles and responsibilities
Incident response skills and mechanisms are vital when handling new or large-scale events. Handling unclear security events requires cross-organizational discipline, bias for decisive action, and the ability to deliver results.
Developers should work with stakeholders, legal counsel, and organizational leadership to identify goals in responding to an incident. Some common goals include containing and mitigating the issue, recovering the affected resources, preserving data for forensics, and attribution. Developers should consider these roles and responsibilities, and whether any third parties should be involved.
Here is a list of security stakeholders:
-
Application owners. Developers might need to contact owners of impacted applications or resources because they are subject matter experts (SMEs) that can provide information and context. Application owners or SMEs might be required to act in situations where the environment is unfamiliar, has unanticipated complexity, or where the responders do not have access. SMEs should practice and become comfortable working with the IR team.
-
Information security. The Information Security team will be the primary contact point when an event or incident is identified. They can respond by investigating, remediating, and preventing incidents from occurring.
-
Legal. The Legal team provides guidance in understanding any legal impacts a security incident may have. This includes crafting communication for all affected parties, including contractors, service providers, customers, and regulatory authorities.
-
Chief, Business, and Information Security Officers. Information security leadership, including the Chief Information Security Officer (CISO) will need to remain abreast of the developer’s security health. In coordination with the Information Security and Legal teams, the CISO leads the organization to prevent, detect, remediate, and communicate incident response in accordance with laws and best practices.
-
The rest of the organization. The overall organization should be aware of potential risks and appropriate reporting mechanisms. Information security awareness training can help the staff (technical and non-technical) prevent security events from occurring, identify indicators of incidents, and report potential incidents to the security team.
-
Third parties. Trusted partners can help in investigation and response, providing additional expertise and valuable scrutiny. Such partners include third parties who contractually require notification that an incident occurred. Specifically, Amazon requires developers to inform Amazon, via email to security@amazon.com, within 24 hours of detecting any security incidents. Alternatively, service providers might include terms and conditions for areas of information security for which they are responsible. Such providers or partners might include Cloud Service Providers (CSPs) who own a portion of the security responsibilities within the environment. Figure 2 shows a typical representation of the shared responsibility model as it applies to AWS. AWS owns the security OF the cloud, providing the highest levels of security possible. Their customers are responsible for the security of their resources in the cloud, keeping its content secure and compliant.
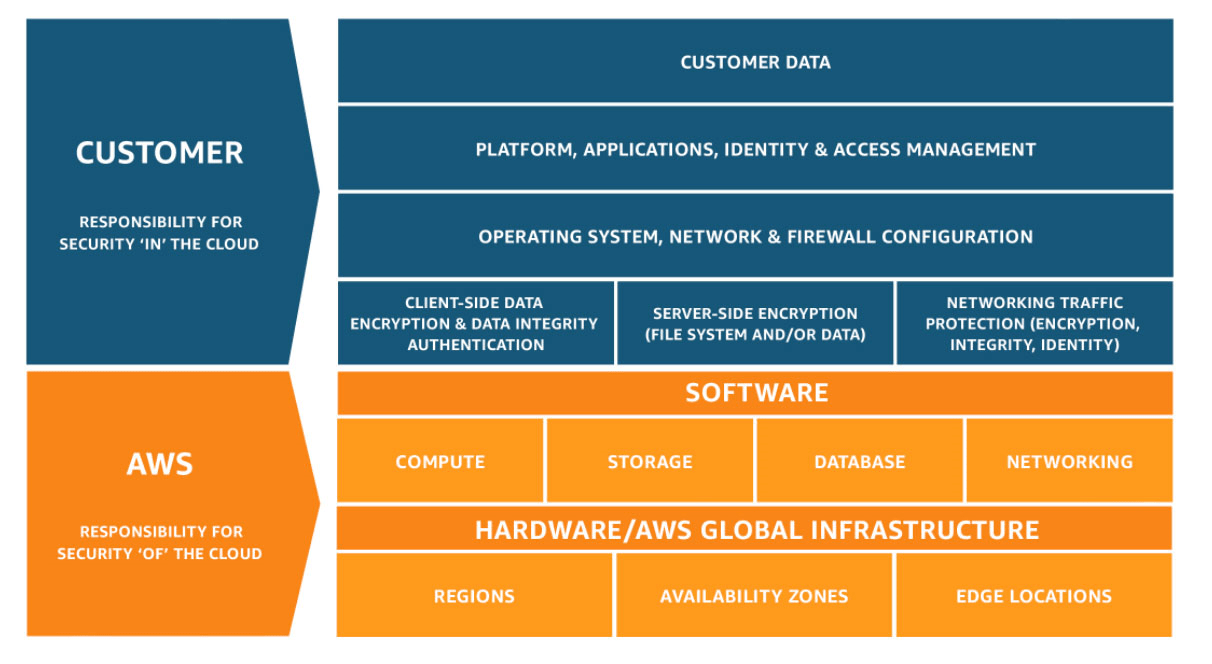
Notification and response
The appropriate parties, such as Amazon, should receive notification of an event occurring so that they can respond in accordance with the processes. Otherwise, the event will go undetected and cause greater damage to the systems.
Developers should implement monitoring systems that can automatically alert after an event has occurred. Common notification mechanisms include emails, ticketing systems, pagers, alarms, and short message service (SMS). Developers should have sufficient tools to respond to the incident in accordance with the response objectives.
Developers should implement response patterns when the event occurs. Documenting an incident is crucial. This preserves relevant information such as the incident description, remediation actions, and controls implemented to help prevent future recurrence. Per the Amazon DPP, developers should document the incident description, remediation actions, and associated corrective process/system controls implemented to prevent future recurrence, if applicable. Additionally, creating documentation aids in escalating the issue to internal stakeholders, partners, and affected parties.
Developers using NIST 800-53 may refer to IR-4: Incident Handling. Effective incident response means handling an incident in accordance with best practices and internal plans. Incident handling and incident response plans are interconnected. Each supports the other as developers strengthen their incident handling and response capabilities. Control IR-4 supports this, and following each portion of the control will help developers comply with the Amazon DPP. While not required, we recommend Developers consider implementing the control enhancements in this domain. These enhancements help developers become well equipped to respond to different types of incidents and certify the health and success of their operations.
NIST control IR-6: Incident Reporting helps define the personnel in an escalation path. This is the chain of people that should remain informed should an incident take place. Developers should define an escalation path so that critical stakeholders and legal counsel remain informed of an incident and can assist the security team in taking action. Relevant stakeholders will remain informed of the incident, its effects, and its status, all of which are necessary in the event that the developer is legally or contractually obligated to notify an outside party. Developers should understand the legal and contractual requirements for reporting an incident, to whom, and when. Similarly, developers should develop objectives to abide by those requirements. Developers should verify that the escalation path and notification procedures include all parties with a legal or contractual right to know.
Developers should validate that the escalation path and notification procedures include all parties with a legal or contractual right to know. For example, GDPR mandates that data controllers should notify the relevant supervisory authority within 72 hours after verifying that certain types of personal data breaches have occurred. Similarly, the Amazon Data Protection Policy requires that developers inform Amazon (via email to security@amazon.com) within 24 hours of detecting an incident.
Preserve evidence
Developers should verify that they are collecting, storing, and protecting logs that capture all critical actions within the environment. At minimum, these logs should contain:
-
The success or failure of the event.
-
The date and time.
-
Access attempts.
-
Data changes.
-
System errors.
Developers with access to Amazon information should ensure that logs do not contain Personally Identifiable Information. Logs should be retained for at least 90 days for reference in the case of a security incident.
Developers should protect logs from accidental or intentional deletions by storing them in a secure location with access granted only to the required personnel. Log information is vital to understanding what, how, and when a system was compromised. Developers should preserve logs, drives, and other evidence by copying them to a centralized account.
Developers should develop and maintain a chain of custody to maintain the information’s integrity by logging who accessed the information, to whom it was given, and all actions taken. These practices give developers the ability to assert whether the affected systems were altered, and to provide assurance that the investigation's findings are accurate. Developers who follow the NIST 800-53 framework may refer to control AU-10(3): NonRepudiation | Chain of Custody. While Audit and Accountability (AU) is not within the IR domain, this control can help define and maintain a chain of custody process. In addition to maintaining compliance with the Amazon DPP, a chain of custody can assist in taking action against an intruder in a court of law, if necessary.
Developers who want to know more about Logging and Monitoring should read the Amazon SP-API Logging and Monitoring whitepaper to understand how to implement compliant logs.
Continuous review
Developers should thoroughly test, review, and regularly update their Incident Response Plan. Otherwise, developers will not be equipped to quickly respond to and resolve security incidents. Amazon requires developers to review and verify the plan every six months and after any major infrastructure or significant system changes. Such changes might include:
-
System. System changes, such as developing new software, using new tools, or deprecating existing tools may increase the likelihood of potential issues.
-
Controls. Implementing new controls or experiencing control failures may affect the Developer’s exposure.
-
Operational environments. Shifting from on-premise to cloud environments, or vice versa, may introduce new complexities in the systems. Developers should conduct risk assessments to understand the new risks that such a change may introduce.
-
Supply chain. Changes in the supply chain, such as changing hardware providers or changing contractor firms, may introduce new risks. For example, a particular hardware provider may be known to inform its customers of technical issue patches quickly, but a lower-cost competitor may not offer that service. In this case, the latter’s customers should account for the fact that they will need to actively protect their infrastructure against common web exploits like SQL injection and implement those patches.
-
Risk levels. Risk levels fluctuate due to the aforementioned factors. Developers should consider implementing an acceptable level of risk for the business and reviewing the incident response plan if that risk reaches its threshold.
Frequent reviews are also valuable. If developers identify gaps in processes or tools during normal operations, they should plan to fix them. These gaps may be self-identified or may occur after a major system change or incident. Developers should implement corrective processes and controls to detect and prevent future incidents. Afterward, developers should update the incident response plan to reflect the lessons learned and processes implemented.
After designing and building the incident response plan, developers should test it prior to an actual event occurring. Developers should establish a frequency whereby the security team simulates a security incident and tests the processes accordingly. Simulations are safe methods to find risk vectors and improve controls and processes. The simulations will also satisfy Amazon’s requirement to review and verify the Incident Response plan every six months.
For each scenario outlined, developers should update the response plan accordingly and notify stakeholders if any changes arise.
Additional resources
Industry References
Document Revisions
| Date | Description |
|---|---|
| September 2022 | Second publication |
| January 2020 | First publication |
Notices
Amazon sellers and developers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents current practices, which are subject to change without notice, and (c) does not create any commitments or assurances from Amazon.com Services LLC (Amazon) and its affiliates, suppliers, or li-censors. Amazon SP-API products or services are provided “as is” without warranties, representations, or conditions of any kind, whether expressed or implied. This document is not part of, nor does it modify, any agreement between Amazon and any party.
© 2025 Amazon.com Services LLC or its affiliates. All rights reserved.
Updated 18 days ago