Protect Amazon API Applications with Data Retention and Recovery
Data retention and recovery procedures to help ensure access to data and reduce data exposure.
Different data types require various retention times, which complicates the balance of keeping data readily available for use and also maintaining legal, business, and personal requirements. Establishing data retention and recovery procedures helps ensure access to data, such as Personally Identifiable Information (PII), is available for as long as required to operate the business while simultaneously reducing the risk of data exposure.
Data protection policy requirements
As stated in the Amazon Services API Data Protection Policy:
Developers will retain PII for no longer than 30 days after order delivery and only for the purpose of, and as long as is necessary to (i) fulfill orders, (ii) calculate and remit taxes, (iii) produce tax invoices and other legally required documents, and (iv) meet legal requirements, including tax or regulatory requirements. Developers can retain data for more than 30 days after order delivery only if required by law and only for the purposes of complying with that law. Per sections 1.5 (“Encryption in Transit”) and 2.4 (”Encryption at Rest”) at no point should PII be transmitted or stored unprotected.
Foundation of data retention and recovery
Keeping Amazon customer PII private is important to ensure the integrity of the buyer’s identity. This type of information requires protection because it can be used for unsolicited marketing, to commit fraud, or to steal an individual’s identity. Deleting content that is no longer needed reduces the risk of litigation and security breaches.
Developers can leverage NIST-800-53 control SI-12: Information Management and Retention. The intent of this control is to ensure that information, including PII, is retained in accordance with regulatory, contractual, and business requirements.
Developers should also consider all applicable requirements. These requirements determine the information retention period, including cases beyond system disposal. Developers can still obtain historical information as needed to fulfill their obligations by contacting Developer Support.
Developers should be familiar with the following important terminology:
-
Personally identifiable information (PII) is information that, when used alone or with other relevant data, can identify an individual.
-
Data retention is the process of storing data for compliance or business reasons.
-
Data retention period is the amount of time that an organization stores a particular type of data. Different data types should have different retention periods.
-
Archiving is the process of moving data that is no longer being used to a separate storage device or location for retention, preferably cold storage.
-
Cold storage is a storage medium for inactive and infrequently accessed data.
-
Backup is a copy of data made in case something happens to the original. When a policy is applied to that backup copy, it is known as backup data retention.
-
Destruction is defined as physical or technical destruction of data that makes it irretrievable by ordinary commercially available means.
Data collection
Before collecting Amazon customer PII, an organization must determine two things:
-
The business need for customer PII.
-
Who should have access to the data.
Developer requirements for Amazon customer PII must comply with the Amazon Services API Data Protection Policy.
Developers are required to retain Amazon customer PII only for as long as it is necessary to fulfill orders or to calculate/remit taxes on behalf of sellers. Amazon customer PII should not be stored in developer systems for longer than 30 days after order shipment.
If a developer is required by law to retain copies of Amazon customer PII for tax, legal, or similar regulatory purposes, this Amazon information can be stored in a cold, or offline, backup store in a physically secure facility.
All data archived on backup media must be encrypted. This traditionally requires expensive, purpose-built hardware and can quickly raise storage costs as the volume of data retention increases. Using cloud storage such as Amazon Simple Storage Service Glacier (Amazon S3 Glacier) for long-term archiving allows organizations to store data cost-effectively for years or even decades. With this approach organizations can offload the administrative task of managing and scaling storage.
If use of cold storage is not in line with business use cases and data must remain in production, developers must ensure that PII information obtained through SP-API that is retained and transmitted through developer systems is encrypted at all times.
Developers must also ensure that only authorized personnel have access to this data. Refer to Protecting Amazon API Applications: Data Encryption for more information about encryption.
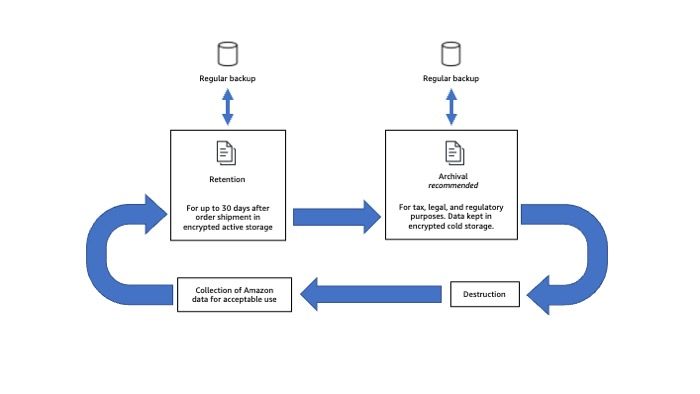
Retention
When creating or revising a data retention plan developers must:
-
Create a data retention policy. This policy must comply with the Amazon Data Protection Policy and should meet the developer's legal requirements.
-
Automate data retention tasks. This should be done in such a way that tasks can be easily changed as requirements change. Amazon S3 Glacier is an example of a cloud-based archive that can automatically archive data based on a policy. For more information about Amazon S3 Glacier, refer to the Archiving section.
-
Consider whether data should be archived or deleted. Deletion is permanent, but archiving incurs running costs. Implement different lifecycles for different data types and use cases. For example, fulfillment has different legal and business requirements than tax use cases.
-
Delete Amazon information when it is no longer necessary or no longer subject to other retention obligations.
-
Keep Amazon sellers informed about data retention practices you follow and the basis on which sellers must access and process Amazon customer PII.
-
Back up and secure Amazon information at all times. This must be done in accordance with SP-API policies. This is important for data retention and data management in general.
Archiving
When there is a need to preserve Amazon information for compliance or regulatory reasons, developers should archive information whenever possible. Unlike creating a backup, which is keeping a copy of production data for a short time to recover from data corruption or loss, archiving maintains all copies of the data until the retention policy expires.
A good archive system has the following features:
-
Data durability for long-term integrity
-
Data security
-
Ease of recoverability
-
Low cost
Developers using NIST 800-53 as their framework can refer to control MP-4: Media Storage. Although this control is part of the Media Protection (MP) domain and SP-API developers should archive and store archived information in a cold, or offline, back-up housed in a physically secured facility. MP-4 specifically requires protection of media by physically controlling and securely storing media, as well disposing of media correctly. Developers can further enhance this control by implementing cryptographic protection as outlined in SC-28(1). Consider leveraging cold storage options on public clouds to meet the requirements of this control.
Archiving data with Amazon Web Services (AWS)
Amazon Simple Storage Service Glacier (Amazon S3 Glacier) is a secure, durable, and low-cost solution for data archiving and long-term backup. Additionally, it provides native encryption of data at rest, 99.999999999% (11 nines) of durability, and unlimited capacity. Amazon S3 Glacier customers can store data for as little as $1 per terabyte per month. Amazon S3 Glacier also provides three options for access to archives, with retrieval times ranging from milliseconds, to a few minutes, to several hours.
Amazon S3 Standard-Infrequent Access is a good choice for use cases that require quick retrieval of data. Amazon S3 Glacier is a good choice for use cases where data is infrequently accessed and retrieval times of several hours are acceptable.
Objects are tiered into Amazon S3 Glacier either through lifecycle rules in Simple Storage Service (Amazon S3) or the Amazon S3 Glacier API. The Amazon S3 Glacier Vault Lock feature allows users to easily deploy and enforce compliance controls for individual Amazon Glacier vaults with a vault lock policy. Developers can specify controls such as write-once-read-many (WORM) in a vault lock policy and lock the policy from future edits.
Here is a visual representation of how AWS products can be used to satisfy data retention and recovery requirements:
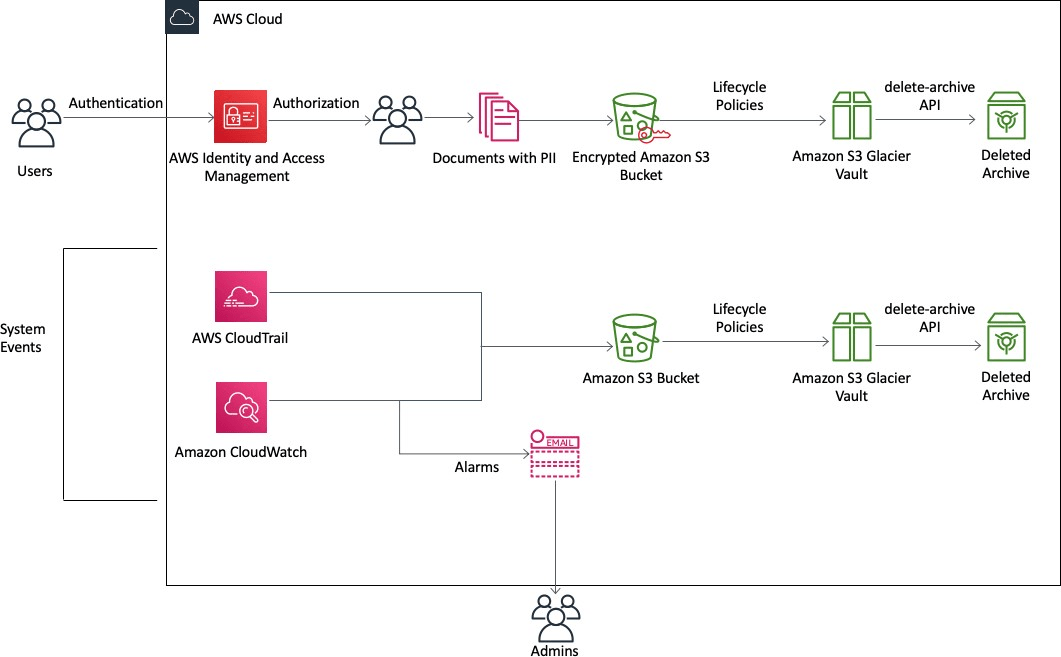
In the preceding figure, users access the AWS Cloud through authentication and then upload documents containing PII into an encrypted Amazon S3 bucket. Lifecycle policies can then be used to automatically shift data from the Amazon S3 bucket into an Amazon S3 Glacier vault. After information is no longer required for regulatory purposes, the Amazon S3 Glacier delete-archive API is called to delete the information.
Additionally, AWS CloudTrail and AWS CloudWatch are enabled to log actions in the environment and notify administrators via email if an event occurs. The logs, stored in Amazon S3 buckets, are also subject to lifecycle policies. This helps to eliminate unnecessary storage costs.
For more information, refer to What is Amazon S3 Glacier and Set Up a Compliant Archive.
Hybrid scenario
This section is for developers who use a large hybrid environment. Let's say a developer is managing an environment used to back up Amazon EC2 instances, standalone servers, virtual machines, and databases.
This environment has 1,000 servers. The operating system, file data, virtual machine images, and databases are backed up. There are 20 databases (a mixture of MySQL, Microsoft SQL Server, and Oracle) to back up. The backup software has agents that back up operating systems, virtual machine images, data volumes, SQL Server databases, and Oracle databases (using RMAN).
For applications like MySQL for which the backup software does not have an agent, the mysqldump client utility can be used to create a database dump file to disk. The standard backup agents can then protect the data.
To protect this environment, the third-party backup software in use might have a global catalog server or a master server that controls the backup, archive, and restore activities as well as multiple media servers. This server can be connected to disk-based storage, Linear Tape-Open (LTO) tape drives, and AWS storage services.
To augment this backup solution with AWS storage services, developers should consider using a backup vendor that uses Amazon S3 or Amazon S3 Glacier. Amazon suggests working with vendors to understand their integration and connector options. For a list of backup software vendors who work with AWS, refer to the AWS partner directory.
If the existing backup software does not natively support cloud storage for backup or archive, you can use a storage gateway device. This storage gateway acts as a bridge between the backup software and Amazon S3 or Amazon S3 Glacier. There are many third-party gateway solutions available to bridge between the two storage mediums, refer to the AWS partner directory.
If you decide to go with an AWS solution, AWS Storage Gateway virtual appliances is one example of such a solution used to bridge this gap because it uses generic techniques such as iSCSI-based volumes and virtual tape libraries (VTLs). This configuration requires a supported hypervisor (VMware or MicrosoftHyper-V) and local storage to host the appliance.
Destruction
To properly delete data, developers must delete it from live data stores as well as any backups or other copies. This means that developers must set up an appropriate retention mechanism on these additional backups and copies that is in line with their business purpose. Data anonymization is not considered an acceptable method for Amazon information deletion. For example, hashing Amazon customer PII to anonymize it in data stores is not an acceptable alternative to deleting Amazon information.
Amazon data destruction criteria
This section discusses the minimum criteria Amazon requires for data to be considered securely deleted.
Case 1 – Directly managing data
To stay consistent with industry standards when directly managing data (for example, storing data on an instance instead of using cloud service for persistent storage), developers must do the following three things to ensure data is deleted securely:
-
Ensure that the data is not recoverable by the customer. This includes via an API or other existing mechanisms that can be used to access the data.
-
Logically disassociate the data (for example, through removing pointers or unlinking index files (inodes) to data). This action commonly overlaps with the first criteria.
-
Mark the media space that contains the deleted data that will be reallocated by the service.
Case 2 – Using a cloud service
When using a service such as Amazon S3 or Amazon DynamoDB for managing data, the service must call a supported delete mechanism of the service in which it stores data. This can be accomplished by using a “delete” API or by implementing a “time to live” mechanism.
Removing pointers to Amazon S3 objects and orphaning data in the service account are not acceptable delete actions.
Acceptable methods for destruction of Amazon data
This section provides an overview of acceptable methods for destroying Amazon data.
-
Clear: This operation renders data on a device unreadable through “keyboard attacks,” meaning a user using forensic applications but not laboratory techniques. A clear operation might involve one or more overwrite passes of the device, firmware erase commands, or other methods as defined in NIST SP800-88r1.
-
Purge: This operation renders data on a device unreadable through laboratory recovery techniques. A purge operation might involve advanced firmware erase commands, key scrambling on self-encrypting drives, or other methods as defined in NIST SP800-88r1.
-
Physical Destruction: This category, as described in the following subsections, might include crushing, pulverizing, shredding, incinerating, and degaussing. It renders data on the device unrecoverable and the device itself unusable.
-
Degaussing: Applies a magnetic field with strength sufficient to overcome the magnetic coercivity of magnetic media. This is only effective on magnetic media, and the coercivity of media varies between models and manufacturers. Developers should get information directly from the manufacturer to properly calibrate a degausser for a given device.
-
Crushing: Applying a large compressive force to a device to destroy it.
-
Pulverizing: Reducing a device to small particles.
-
Shredding: Cutting media into small parts that cannot be re-assembled. For maximum effectiveness, the cut parts should be smaller than the physical area required to store a block of data.
-
Incinerating: Applying extreme heat to a device in order to destroy it through burning or melting. Heating past the Curie point of magnetic media (the maximum temperature a material can reach before losing or changing its magnetic properties) is also effective.
Conclusion
Data lifecycle management is an important part of securing data. All data, especially PII, must have defined terms around storage length, usage, and destruction. Practicing good data hygiene through retaining and maintaining data for as long as it’s needed and destroying when it is not needed, helps to limit the blast radius or amount of data exposed during a security incident. Some authorities and regulatory bodies will have defined standards on how long an organization should retain data, but even without these standards, you should still define how long data is retained. As it so happens similarly with other assets, the longer you keep data around “just in case” it’s needed, the more costs associated with storage mediums, locations to store it, and training personnel on proper handling, will increase.
Additional resources
Industry references
-
NIST Special Publication 800-88 Revision 1: Guidelines for Media Sanitization
-
NIST 800-53 Rev.5: Security and Privacy Controls for Information Systems and Organizations
Document revisions
| Date | Description |
|---|---|
| December 2022 | Revised for technical accuracy |
| January 2020 | First publication |
Notices
Amazon sellers and developers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents current practices, which are subject to change without notice, and (c) does not create any commitments or assurances from Amazon.com Services LLC (Amazon) and its affiliates, suppliers, or licensors. Amazon Selling Partner API (Amazon SP-API) products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. The responsibilities and liabilities of Amazon regarding SP-API are controlled by Amazon’s SP-API agreements (including the Amazon Selling Partner API Developer Agreement or the Amazon Selling Partner API License Agreement), and this document is not part of, nor does it modify, any agreement between Amazon and any party.
© 2025 Amazon.com Services LLC or its affiliates. All rights reserved.
Updated about 1 month ago